Teaching robots novel skills with demonstrations via human-in-the-loop data collection techniques like kinesthetic teaching or teleoperation puts a heavy burden on human supervisors. In contrast to this paradigm, it is often significantly easier to provide raw, action-free visual data of tasks being performed. Moreover, this data can even be mined from video datasets or the web. Ideally, this data can serve to guide robot learning for new tasks in novel environments, informing both what to do and how to do it. A powerful way to encode both the what and the how is to infer a well-shaped reward function for reinforcement learning. The challenge is determining how to ground visual demonstration inputs into a well-shaped and informative reward function. We propose a technique Rank2Reward for learning behaviors from videos of tasks being performed without access to any low-level states and actions. We do so by leveraging the videos to learn a reward function that measures incremental progress through a task by learning how to temporally rank the video frames in a demonstration. By inferring an appropriate ranking, the reward function is able to guide reinforcement learning by indicating when task progress is being made. This ranking function can be integrated into an adversarial imitation learning scheme resulting in an algorithm that can learn behaviors without exploiting the learned reward function. We demonstrate the effectiveness of Rank2Reward at learning behaviors from raw video on a number of tabletop manipulation tasks in both simulations and on a real-world robotic arm. We also demonstrate how Rank2Reward can be easily extended to be applicable to web-scale video datasets.
We evaluate Rank2Reward on six different real-world tasks. In addition to standard tasks like reaching and pushing, our more complex tasks highlight situations where exploration is non-trivial, techniques like object tracking are ineffective, and reward specification overall is difficult.

Reach

Reach

Push w/ Obstacle

Sweep

Drawer Open

Draw
We evaluate Rank2Reward on six different real-world tasks. In addition to standard tasks like reaching and pushing, our more complex tasks highlight situations where exploration is non-trivial, techniques like object tracking are ineffective, and reward specification overall is difficult.

Reach

Push

Hammer

Drawer Open

Door Open

Door Close

Button Press

Assembly
We scale Rank2Reward to a large-scale egocentric dataset, utilizing 20,000 segments of object interactions. From each clip, we utilize the last frame as the goal frame and learn a ranking component conditioned on the goal frame. For the discriminator, we sample a positive frame from the same clip as a goal and a negative frame from a different clip as the goal, and train the discriminator to classify whether the given frame and the goal frame come from the same video. These negative frames with goals that do not match can be considered counterfeit or counterfactual examples.
We randomly select segments from the unseen evaluation set and present the output of Rank2Reward when evaluated with the true goal and a counterfactual goal. The ranking for the true goal is overall increasing whereas the counterfeit goal is not and overall has a lower reward than the true goal.
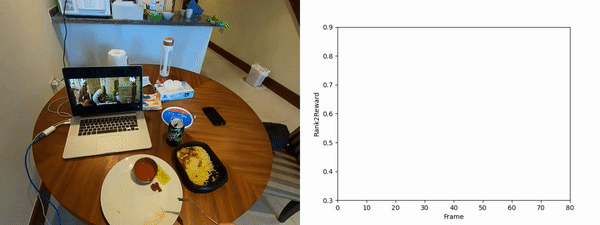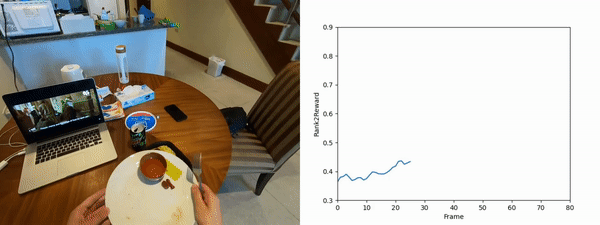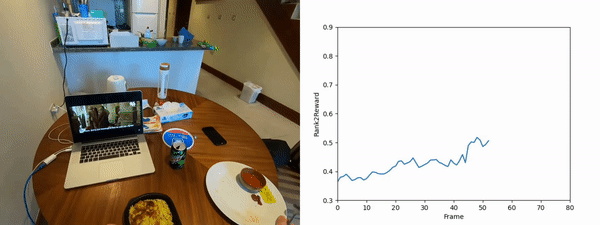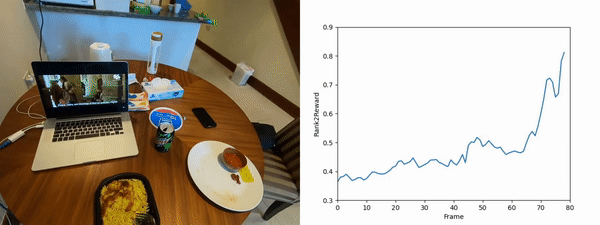
Rearranging a plate and rice
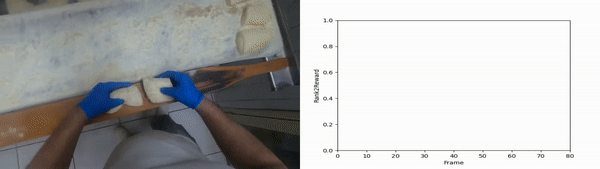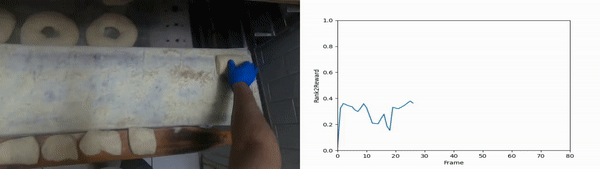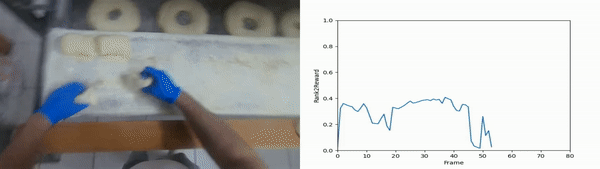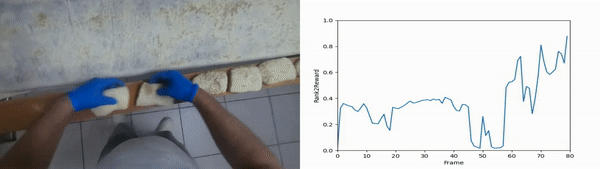
Moving bread dough on an assembly line

Bringing a water bottle to mouth and unscrewing the cap
@article{yang2024rank,
author = {Yang, Daniel and Tjia, Davin and Berg, Jacob and Damen, Dima and Agrawal, Pulkit and Gupta, Abhishek},
title = {Rank2Reward: Learning Shaped Reward Functions from Passive Video},
journal = {ICRA},
year = {2024},
}